|
In the editing phase, a decision-maker organizes and reformulates the available options, so as to simplify the choice. It consists of the following operations:
- Coding: People perceive outcomes as gains and losses, as seen above, rather than final states of wealth or welfare. A gain or loss is, of course, defined with respect to some reference point. The location of the reference point affects whether the outcomes are coded as gains or losses.
- Combination: Prospects are simplified by combining the probabilities associated with idential outcomes. For example, the prospect (200, 0.25; 200, 0.25) will be reduced to (200, 0.5).
- Segregation: The riskless component of any prospect is separated from its risky component. For example, the prospect (300, 0.8; 200, 0.2) is decomposed into a sure gain of 200 and the risky prospect (100, 0.8). The same process is applied for losses.
The above operations are applied to each prospect separately. The following are applied to two or more prospects:
- Cancellation: One form of cancellation is the isolation effect, described above. Cancellation also involves discarding common outcome-probability pairs between choices. For example, the pairs (200, 0.2; 100, 0.5; 20, 0.3) and (200, 0.2; 300, 0.4; -50, 0.4) are reduced to (100, 0.5; 20, 0.3) and (300, 0.4; -50, 0.4).
- Simplification: Prospects are likely to be rounded off - a prospect of (51, 0.49) is likely to be seen as an even chance to win 50. Also, extremely unlikely outcomes are likely to be discarded.
- Detection of Dominance: Outcomes which are strictly dominated are scanned and rejected without further evaluation.
|
|
Note: Some editing operations will permit or prevent others from being carried out. The sequence of editing operations is likely to vary with the offered set and the format of the display.
Many preference anomalies arise from the act of editing. For example, inconsistencies described by the isolation effect result from the cancellation of common components. Some intransitivities can result from a simplification that eliminates small differences between prospects.
|
|
In the evaluation phase, an individual examines all the editied prospects and chooses the one with the highest value. The overall value of a prospect, denoted by V, is expressed in terms of two scales, π and v.
The first scale, π, associates a decision weight π(p) with each probability p. This reflects the impact of p on the overall value of the prospect. It is important to note that π is not a probability measure, and Kahneman and Tversky prove that π(p) + π(1-p) is frequently less than 1.
The second scale, v, assigns a number v(x) to each outcome x, which reflects the subjective value of that outcome. Recall that outcomes are defined relative to a reference point, which serves as a zero point, so v measures deviations from that reference point.
For a simple prospect of the form (x,p; y,q), where the individual receives x with probability p, y with probability q, and nothing with probability 1-p-q, where p + q 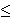 1, we say that: 1, we say that:
An offered prospect is strictly positive if its outcomes are all positive, i.e. x, y > 0 and p + q = 1.
It is strictly negative if all its outcomes are negative.
It is regular if it is neither strictly positive, nor strictly negative.
So for a regular prospect, i.e. either p + q < 1, or, without loss of generality, x 0 y, then:
V(x, p; y, q) = π(p)v(x) + π(q)v(y),
where v(0) = 0, π(0) = 0, and π(1) = 1. V is defined on prospects, while v is defined on outcomes.
The evaluation of strictly positive or strictly negative prospects follows a different rule, described below:
If p + q = 1, and either x > y > 0, or x < y < 0, then:
V(x, p; y, q) = v(y) + π(p)[v(x) - v(y)],
so the value of a strictly positive or strictly negative prospect equals the value of the riskless component plus the differences between the values of the two outcomes, multiplied by the weight associated with the more extreme outcome. Note that a decision weight is applied only to the risky component, not the riskless one.
Example:
V(400,0.25; 100,0.75) = v(100) + π(0.25)[v(400) - v(100)]
Note that a decision weight is applied to the value difference v(x) - v(y), but not to the riskless component, v(100).
Also note that the equation above reduces to π(p)v(x) + [1-π(p)]v(y). This reduces to π(p)v(x) + π(q)v(y), the equation for a regular prospect, if π(p) + π(1-p) = 1. However, this is not generally satisfied.
While the prospect theory equations appear to resemble those of expected utility theory, the crucial differences are:
- Values are attached to changes, rather than final states, and
- The decision weights need not coincide with probabilities.
|

 Printer Friendly
Printer Friendly

